As you well know, one of the main advantages of algorithmic trading is that it allows traders to automate their strategies and execute orders at speeds and levels of precision that would be impossible to achieve manually. However…
The effectiveness of any algorithmic trading strategy depends not only on its underlying logic, but also on the robustness of the infrastructure that supports it.
For this reason, in this post I want to emphasize the importance of a well-designed algorithmic trading infrastructure and explain what its essential components are. This way, you will have a foundation that can serve as a starting point for developing your own ideas.
The Importance of Having Your Own Algorithmic Trading Infrastructure
Building your own algorithmic trading infrastructure is not just a technical exercise; it is an investment in efficiency and adaptability for your entire operational process: from researching your strategies to the actual execution of trades.
I am aware that the idea of creating an algorithmic trading infrastructure from scratch may seem like a daunting task, as it is a large-scale project that requires time and specific knowledge. In fact, at KomaLogic it took us around half a year to have a version robust enough to start using it.
Even so, there is still a lot to improve. However, all team members firmly believed that the benefits far outweighed the risks, and for this reason we decided to develop it. In case it serves as motivation, looking back now, I believe it was a very good decision.
Having a custom infrastructure gives you full control over your trading environment, allowing you to tailor every aspect to your specific needs. This not only improves operational efficiency but also offers unparalleled flexibility to adjust or expand your system as your trading approach and style evolve.
It is true that generic or third-party platforms and solutions offer a more accessible entry point into the world of systematic trading. In fact, I believe every beginner should start there before considering building their own algorithmic trading infrastructure. However, as a trader gains experience and their needs advance, they eventually require more customization and control over the tools they use.
That said, using third-party tools also exposes you to the risk of those tools changing, failing to update, or simply disappearing. It is true that for well-established platforms such as TradeStation or MultiCharts this possibility is very remote, but not nonexistent. We simply need to be aware of this risk, its likelihood, and decide whether we are willing to take it or not.
At the same time, you may also end up working with multiple platforms because one offers functionality X, another offers Y, but they cannot communicate with each other. This forces you to build spreadsheets or other adapters in order to, for example, extract data from one platform and load it into another. In the end, your infrastructure becomes a kind of Frankenstein of multiple technologies that is very difficult to maintain and use.
These are the reasons that should be placed on your pros and cons list so that you can decide whether it makes sense for you to build your own version or to continue using already commercialized platforms.
Finally, and I believe this is the most important point, by building your own algorithmic trading infrastructure you become intimately familiar with each of its components, which in turn makes it much easier to detect and correct errors, update systems, and implement new strategies in a far more straightforward manner.
The Key Components of a Robust Algorithmic Trading Infrastructure
The first step in creating a professional algorithmic trading infrastructure is choosing which technologies you are going to use. For me, Python is without a doubt the best option given its versatility and the availability of libraries. On the other hand, if your framework has parts that are latency-sensitive and require greater processing speed than Python can offer, you can turn to languages such as Go, Rust, or C/C++ to program those sections.
Next, you will need to establish the various modules that will form the main structure of the operational framework. You should also have a clear idea of how the entire project will be architected, both at the software level and in terms of version management and execution.
This means that, ideally, each module should handle a single task (separation of concerns), so that we can separate functionalities in a way that makes it much more convenient to design, program, test, or modify them.
The ideal approach would be to organize each module into a class that implements a specific interface. This way, we can always keep all the methods of each class well organized, and we will define in advance the capabilities of each module, which in turn facilitates code separation and reusability. This is exactly how we build it in the course, explaining in detail each step and the reasoning behind every decision regarding said architecture.
However, you can also organize the modules into packages of functions if you do not feel entirely comfortable with object-oriented programming. That way you will also be able to separate those functions into groups according to the objective they pursue.
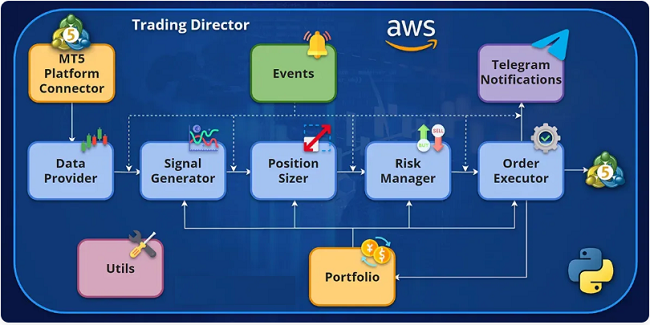
With this in mind, let us now take a look at what the main modules of a complete framework would be.
Data Adapter
Decision-making in trading depends largely on the quality and speed at which new market data is received and processed. For this reason, a module that acts as a data adapter and provider will be the most important component of your algorithmic trading infrastructure. If you think about it, it does not matter how good the rest of the modules in your framework are; without access to new market data, they will not be of much use.
The main objective of this module will be to check whether new data exists in the market. If that is the case, it should process it and be able to deliver it in a standardized format to the other modules that require it. Put more simply, this means that the module responsible for generating trading signals can request the latest market data from the data adapter, and the latter will always deliver it in the same format regardless of the original source.
Another advantage of developing your own data adapter is that you can customize it to access different specific sources. For example, within a single data adapter, you could create several sub-modules: one to retrieve data from your broker’s platform, another that connects to an exchange’s API, and so on.
This way, with a common code base you could already consume data from different sources. And even if the format of this data were different for each source (for example, data coming from MetaTrader 5 is not the same as that from the Interactive Brokers API or the Binance API), the processing and standardization itself would ensure that the data consumed by the rest of your framework’s modules is always in the same format.
Signal Generator
Once market data can be obtained, it is time to calculate whether we have any new trading signal, and this is precisely the job of the signal generator module.
This module is like the analytical heart of your algorithmic trading infrastructure. It consumes the data provided by the data provider and applies the algorithm that encapsulates the appropriate logic to generate trading signals.
For example, if you were using a classification model to generate trading signals, that model would be encoded in the signal generator so that, when new data arrives, it can generate the buy or sell signal.
Using another example, such as the case of a moving average crossover strategy, the signal generator would calculate the new averages corresponding to the newly received data and check whether they have crossed. If so, it would generate a trading signal in the relevant direction.
Modularizing signal generation is also a very interesting concept, as it allows you to create a sub-module for each entry rule you want. It does not matter whether you use a machine learning model or a technical rule to generate your buy or sell signal. Encapsulating it in its own signal generator allows you to reuse that rule or model whenever you need it — meaning you will only have to program it once.
By architecting signal generation this way, it will be very easy to create new entry rules by combining different ones. For example, generating a buy signal only when rules A, B, and C are in agreement, or creating more complex logic such as a majority voting system among different models.
Position Sizer
Next, the position sizing module will be responsible for determining the optimal size for each generated trading signal. In practice, this means deciding how many shares, futures contracts, or lots of a given financial instrument we are going to buy or sell.
Just as was the case before, you will be able to create different sub-modules that encapsulate the logic of different sizing processes. For example, you could have a sub-module that calculates the size of a position based on:
- a risk percentage relative to the account size: for example, risking 0.5% of equity per trade.
- the minimum size that the broker accepts for the specific instrument: for example, 0.01 lots of EURUSD.
- the size based on the Kelly formula
- the historical volatility of the instrument
- or any other method you would like to program.
Having position sizing modularized will help you design and test new strategies faster, since once you have the logic programmed you will also be able to reuse it as many times as you need. This means it will be extremely straightforward to switch from one positioning system to another within the same strategy in order to verify how the different versions would perform.
Risk Manager
I think it goes without saying that risk management is, probably, the most important aspect of a trading strategy. In fact, a winning strategy can easily become a losing one without proper risk management.
For this reason, it is very important to create a module dedicated specifically to the risk management of the strategy. Remember that risk management and position sizing are not the same thing.
Let me give you an example to make this clear:
Imagine you have a strategy that sizes positions based on a percentage of your equity. That strategy has given you 3 consecutive buy signals on EURUSD, so you have 3 open buy positions in the market:
- The first was 1 lot (100K EUR),
- the second was 2 lots (200K EUR),
- and the third was 3 lots (300K EUR).
This is because the price of EURUSD has been rising and your equity value has as well, meaning you are long a total of 6 lots (equivalent to a long exposure of 600K EUR). Since you calculate positions based on a percentage of your equity, each position is larger than the previous one (as each position accumulates gains), just as dictated by your system’s sizing rules.
However, now imagine that the price of EURUSD continues to rise and your strategy gives you another buy signal. At that point, the position sizer recalculates the value and results in a buy signal for 4 more lots. At the strategy level, everything has gone well — you have received buy signals and sized them exactly as the coded logic dictates.
Nevertheless, your risk level is increasing, since a sudden drop in the price of EURUSD could mean a significant loss in your portfolio. Even more so considering that the position you are placing is growing larger each time.
This is why adding a risk management layer is so important. The job of this module will be to analyze your open positions in the market and determine their risk level using a previously defined metric. In the case of the example, the metric could be the exposure to a specific currency. With 6 lots, you have a long exposure of 600K EUR.
Now, the new 4-lot position would bring your exposure to one million euros long (10 lots are equivalent to an exposure of 1M EUR), but you have configured your risk manager to not allow an exposure of more than 750K EUR. This means the risk manager would act as a limiter, and would modify the size of the new position from 4 lots down to just 1.5 lots. These 1.5 lots would be the maximum size that the risk manager would allow in order to continue complying with the defined maximum exposure rules.
The risk management module can also make use of the sub-modularity we discussed earlier, as there are different ways to measure the overall risk of your strategy. Here are some examples:
- Maximum exposure to a currency, geographic region, or asset type
- Maximum leverage factor
- Value-at-Risk (VaR)
- Expected Shortfall (ES)
- Estimated standard deviation of returns
This way, you could also easily swap between them, giving you the flexibility to modify your risk criteria as your strategies or market conditions evolve.
Execution Module
The execution module is the component that takes the trading signals approved by the risk manager and executes them in the market, either through a connection with your broker or directly on an exchange.
This means that, ideally, the execution module should receive the orders to be executed in a standardized format (of your choosing) and then route them to the appropriate destination. This means you will need to create, once again, a sub-module for each destination you intend to trade on.
This way, the same code could, for example, execute orders on the MetaTrader 5 platform or on the Binance exchange, simply by selecting the required execution sub-module. This flexibility is very important, as it makes the creation of new code for strategies much more efficient and, at the same time, reduces the possibility of making errors.
To achieve this, the execution module must have very robust error handling logic, as it will act as a translator between our code and the API of our broker or exchange. In other words, the module will have different connectors that will be used depending on where the strategy is to be executed.
The execution module should offer support for different order types: market orders and pending orders, such as limit and stop orders. Here too you could implement more advanced execution algorithms to minimize transaction costs. For example, by using limit orders instead of executing at market price, or by reducing market impact through splitting a large order into multiple smaller ones.
Portfolio
The Portfolio module should constantly track the status of active trades in the market. This module will be responsible for providing a comprehensive view of all your positions to the rest of the modules that require this information. As I imagine you can already guess, the risk manager will make great use of the portfolio module in order to access open trades and thus calculate the appropriate risk metrics.
This module must be capable of consolidating data from multiple assets and presenting this information in a clear and standardized manner. That is, if the modules of your framework expect to receive position information in a DataFrame but the exchange returns it in a JSON format, you convert from one format to the other so that the different modules receive said data in the standard format you have defined for your architecture.
Efficiency in portfolio management is essential for resource optimization and the effective consumption of information by the other components of the framework.
Event Orchestrator
The event orchestrator is the component responsible for synchronizing all the modules of the infrastructure. That is, it will control that when the data adapter detects a new market quote, that data is sent to the signal generator, then to the position sizer, and so on.
In other words, it will be responsible for orchestrating the entire chain of events that occur from the reception of new market data through to the execution of orders and the updating of the portfolio’s status.
It will be very important that the design of the event orchestrator facilitates the addition of new components or the modification of existing ones, as you will very likely encounter this situation in the future.
In this regard, it is worth investing whatever time is necessary in its design so that when you need to add to or modify the infrastructure, the orchestrator can accommodate that change in the most flexible way possible. This will ensure the scalability of your algorithmic trading infrastructure, along with a much more straightforward maintenance process.
Notification System
Finally, it is necessary to have a notification system that keeps you informed of the status of your trades, alerting you to important events such as the execution of a new position or a disconnection from the platform. This is especially critical in an automated environment, where the speed of your response to such events can mean the difference between a minor correction and a significant loss.
In the course, we have built the notification system to send notifications via Telegram so that you can receive alerts on your phone wherever you are. We do this using the Python Telegram Bot library. However, notifications could also be sent by email or as requests to a REST API to alert any other system.
This will offer you great flexibility by being able to receive real-time alerts no matter where you are. Using an event-driven architecture, you can easily customize this system to notify you of specific events, such as the activation of orders, reaching risk limits, or even unexpected changes in market data.
Local or Cloud Execution
Once you have your algorithmic trading infrastructure built, the time will come to make another crucial decision: running it locally on your own machine or using cloud resources. Both options have significant advantages and disadvantages that you must consider based on your specific trading needs, resources, and objectives.
Running your infrastructure locally offers advantages such as full control over the hardware and software, allowing for absolute customization according to your needs and providing a superior level of privacy and security, by avoiding the transmission of data over the internet (meaning your algorithm resides only on your computer rather than on an external server).
However, this approach means that in the event of a failure of a critical component such as the processor, memory, or hard drive, not only is there a risk of data loss, but the entire trading process would also come to a halt, potentially affecting operational continuity and real-time decision-making.
Despite its benefits, local execution entails additional limitations and responsibilities. Resources are restricted by the available hardware, and the trader must handle system maintenance and updates, which requires time and technical knowledge. Furthermore, scalability is a challenge, and any significant expansion involves considerable investment (new servers, storage, etc.). The possibility of a technical failure bringing all operations to a stop adds a level of risk that must be meticulously managed, including backup and data recovery strategies.
Evidently, these risks will depend on your demands as a trader. If you are trading your own account at a low capital level, it may not make sense for you to move your infrastructure to the cloud, and running it on a low-power computer such as a Raspberry Pi may be sufficient.
However, if you are managing third-party capital (whether directly or through a Darwin, as is the case with KomaLogic and KLV), moving operations to the cloud becomes almost mandatory.
Cloud execution offers scalability and flexibility, allowing you to adjust resources according to demand and access the infrastructure from anywhere. This option reduces the user’s responsibility regarding maintenance and updates, delegating these tasks to the service provider.
Running our infrastructure in the cloud also allows us to choose the data center closest to our broker’s server, thereby reducing communication latency.
The choice between local and cloud execution must take these factors into account, including vulnerability to hardware failures in the local case, which could interrupt operations and compromise data. While the cloud offers advantages in terms of scalability and maintenance, local execution provides superior control and security, albeit with a higher risk of interruption due to technical failures. The final decision should be based on a balance between these considerations, aligning the algorithmic trading infrastructure with the user’s objectives, resources, and risk management strategies.
For us, the advantages offered by the cloud far outweigh its disadvantages, and it is the option we use at KomaLogic. Moreover, if you are curious about how you could run your strategies in the cloud, in the course we show you how to do it step by step. You will find it is much easier and more affordable than you probably think.
Conclusion
Building a custom algorithmic trading infrastructure in Python undoubtedly places you in a very advantageous position to improve the design and execution process of your trading strategies. By having full control over every component, you can experiment with new strategies or technologies and proactively adjust your system to maintain or improve your performance as you gain more experience and knowledge.
This infrastructure not only facilitates the implementation of your trading ideas but also provides you with a deep understanding of its internal mechanics — a very important knowledge that can be the key to identifying improvements or solving problems effectively.
Thank you very much for reading,




